Blog
Engineering notes on AI agents, automation, and the infrastructure behind them.

Your AI Agent Makes Four Bad Decisions a Smarter Model Won't Fix
AI agents fail decisions for the same four reasons people do. The WRAP framework, encoded as a system-prompt gate, fixes what a bigger model can't.

Why Execution-Only AI Agents Fail: Add a Steering Layer
Execution-only AI agents finish every task but never ask if the task was worth doing. The fix is a steering layer over your work.
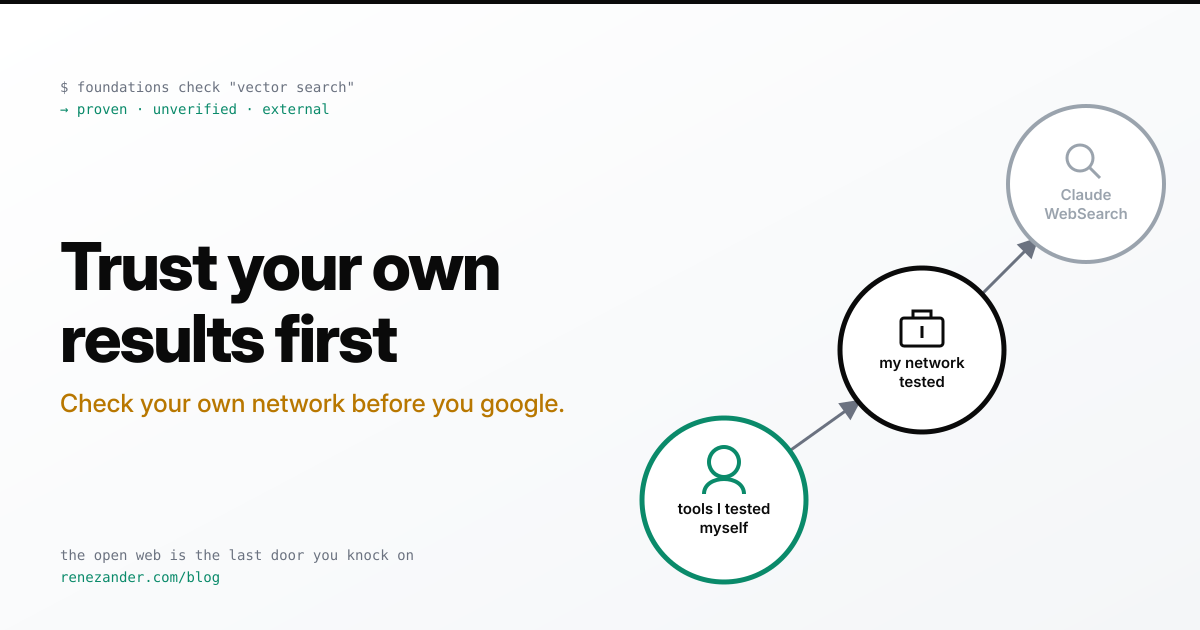
AI Agent Best Practices: Trust Your Own Results Before Google
Your AI agent reaches for googled best practices before your own proven fixes. Wire a trust order into your CLAUDE.md and agent loop instead.

Why AI Coding Agents Skip Your Definition of Done
AI coding agents agree to your process, then skip it. Why review can't catch it, and the one fix that works: a deterministic finish-line gate.

Your Task Manager Is the Best Agent Memory You're Not Using
Agent memory without a new vector DB. Your task app is years of curated, ranked context. ATS gives your agent a hybrid-retrieval channel into it.

AI Agent Model Evaluation: 5 Tests Before the Night Shift
A five-test protocol to catch regressions, compare cost, and canary a new model before it runs an AI agent unattended.

Build the Harness Once With Your Best Model. Run It on a Cheap One.
Agents forget and good ones cost. The fix is not a better model. Put the goal in deterministic scripts and run a cheap model against them.

Most of Your AI Skills Will Rot. Here's Which Ones Compound.
A skill's lifespan is set by what it couples to, not how good the prompt is. Why most AI skills rot, which parts compound, and how to tell.

Claude Code Stops Following Your CLAUDE.md: Read-Once Rules and Hooks
Claude Code reads your CLAUDE.md once at startup, so rules decay as the session fills up. Move the ones that must never break into hooks.

Claude Opus 4.8 Is Out. The Number I Care About Isn't on the Benchmark Chart.
Opus 4.8 shipped May 28. For unattended cron agents, the upgrades that matter are not the benchmark scores. A use-case breakdown from real builds.

Your 50th Skill Makes the First 49 Less Reliable
Past a token-budget threshold, each new skill silently lowers reliability of the rest. Where the work actually lives is below the skill layer.

Self-Hosted Voice AI: Why GDPR Is the Wrong Test (NIS2 Is the Real One)
A GDPR tick isn't a NIS2 test. What you really need to verify with hosted voice AI vendors before NIS2 puts the board on the hook personally.